browser
浏览器是如何工作的
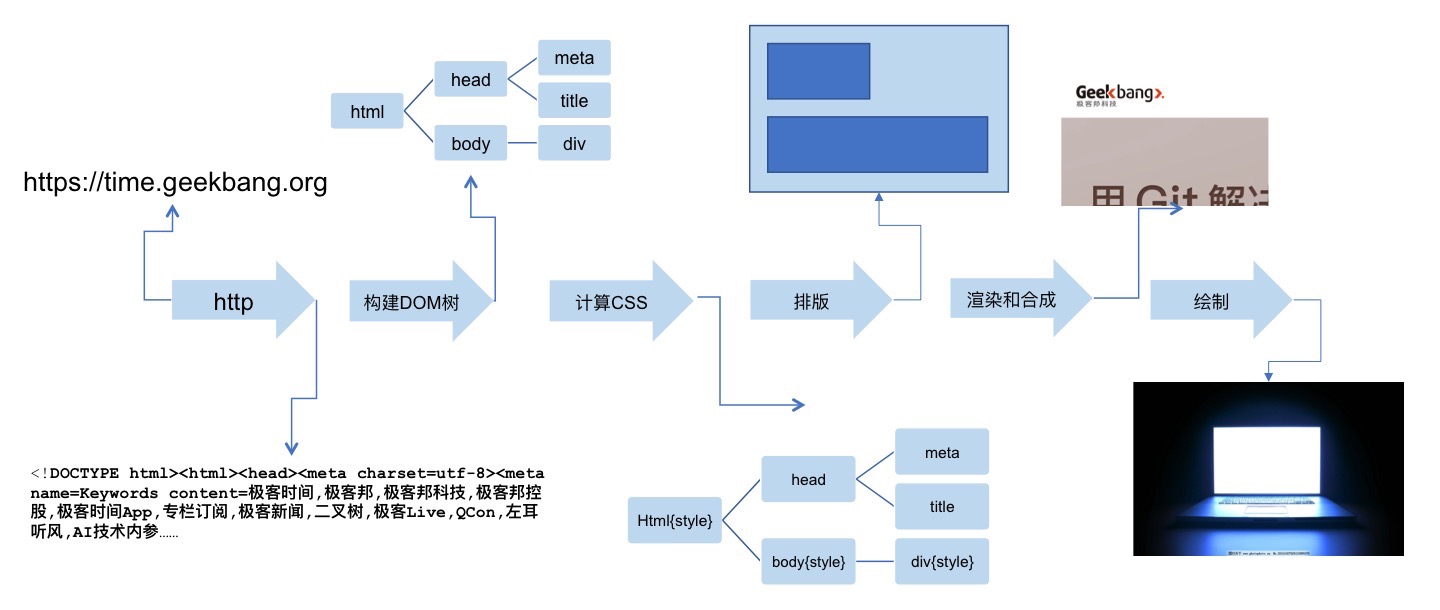
- 浏览器使用 HTTP / HTTPS 协议,向服务端请求页面
- 解析请求到的 HTML 代码,构建成 DOM 树
- 计算 DOM 树上的 CSS 属性
- 根据 CSS 属性,逐个渲染,生成位图
- 对位图进行合成
- 合成后,绘制到界面上
上面的过程是流式的
一、HTTP 协议
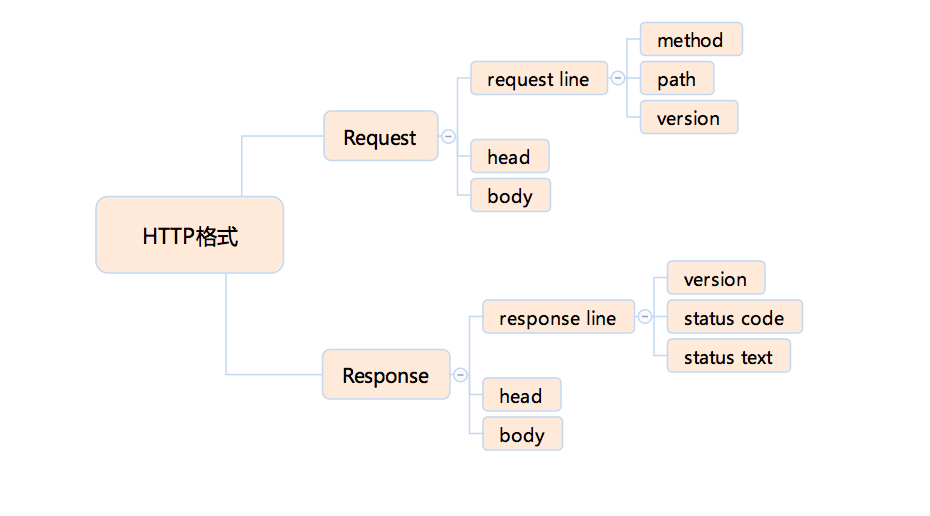
304 协议:
客户端本地有了缓存版本, request 告诉服务端,
服务端通过时间或tag,发现没有更新
返回一个不含 body 的 304 状态
二、解析代码
解析 HTTP 的 Response 的 body。
如:
<p class="a">text text txr</p>
这段代码会依次拆成词(token)
<pclass="a"\>text text txr</p\>
状态机
三、计算 CSS 属性
CSS 计算是把 CSS 规则应用到 DOM 树上,为 DOM 结构添加显示相关属性的过程
四、排版
基本的排版方案是正常流排版,包含了顺次排布和折行等规则。
遵循公认的文字排版规范,规定了**行模型**
**盒模型**
正常流基础上,还支持
- 绝对定位元素
- 浮动元素
五、渲染 - 合成 - 绘制
render : 渲染
特指把模型变成位图的过程
浏览器中的渲染过程:把每一个元素对应的盒变成位图,每个元素可能对应多个盒,每一个盒对应一张位图。
compositing : 合成
合成过程是一个性能考量,并非浏览器的必要一环
根据合成策略,“猜测”可能变化的元素,将他排除到合成之外。
最大限度减少绘制次数
绘制
位图最终绘制到屏幕上,变成肉眼可见的图像,操作系统来处理
绘制发生的频率很高,鼠标滑过浏览器显示区域,每次移动都会造成了重新绘制
CSSOM
CSSOM API
document.styleSheets 获取文档中所有的样式表
CSSOM view
窗口 API
- moveTo(x, y)
- moveBy(x, y)
- resizeTo(x, y)
- resizeBy(x, y)
视口滚动 API
- scrollX
- scrollY
- scroll(x, y)
- scrollBy(x, y)
元素滚动 API
- scrollTop
- scrollLeft
- scrollWidth
- scrollHeight
- scroll(x, y)
- scrollBy(x, y)
- scrollIntoView(arg)
全尺寸信息

事件
鼠标、触摸屏 pointer 设备 -- 捕获和冒泡
捕获是从外向内,是计算机处理事件的逻辑。如操作系统提供坐标给浏览器。
冒泡是从内向外,是人类处理事件的逻辑。如按电视开关,也按到了电视。
建议:默认使用冒泡模式,当开发组件时,遇到需要父元素控制子元素的行为,可以使用捕获机制。
addEventListenner 有三个参数: 事件名,事件处理函数,捕获(true)还是冒泡(false)
第三个参数还可以是对象
- once 只执行一次
- passive 承诺次事件监听不会调用 preventDefault ,有助于性能
- useCapture 是否捕获,否则冒泡
键盘事件 - 焦点系统
焦点系统认为整个 UI 系统中,有且仅有一个“聚焦”的元素,所有的键盘事件的目标元素都是这个聚焦元素。